ウォーターマークをスクラッチでGoで実装した過程で、あまたの改善を行いましたが、その一つを紹介。
「画像のブロック処理のために、先んじて1次元スライスを並べ替える。」です。 メモリ効率は改善しましたが、速度については残念ながら期待する結果が得られませんでした。
| Before | After |
|---|---|
| スライスを左上から行優先 | スライスを左上からブロック/行優先 |

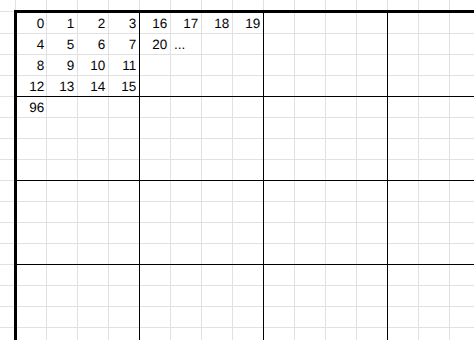
「ブロック」とは画像の分割したまとまりを指します。 例えば「4ピクセル四方のブロックに分割する」としたとき、80ピクセル四方の画像は、横に20個、縦に20個の計400個のブロックに分割できます。
ウォーターマークのアルゴリズムでは、画像の各ブロックに対してやや重たい計算します。 この時、データの順番を予め並び替えることで、CPUキャッシュを活用し、かつスライスのコピーをなくすことで、速度を改善を試みました。
実装詳細
もとのスライスから取得するためにコピーを複数回、かつ計算結果を戻すのに同じだけコピーを行います。 このコピーをしないように、取りやすい形にスライスを並べ替えておくのが今回の改善です。
src := []int{.....}
// block 0番目を取りたい!
// Before
// src の 10 ~ 13, 24 ~ 27, xxx, xxx の4箇所からデータを取らないと行けない!
copy(dist[0], src[0])
copy(dist[1], src[1])
copy(dist[2], src[2])
copy(dist[3], src[3])
// After
// 先にシャッフル
// 一度だけ参照すればOK!
return src[0:8:8]
詳細は以下。
// Before
wavelets := dwt.HaarDWT(img, srcWidth, nil)
src := wavelets[0] // cA
blockAt := 0
for startY := 0; startY < waveletHeight; startY += waveletBlockHeight {
for startX := 0; startX < waveletWidth; startX += waveletBlockWidth {
// ここでsrcからコピー
b := get(src, startX, startY)
// 計算: DCT -> SVD -> 計算 -> 逆変換で戻す
v, idct := dct.Exec(b)
s, isvd, _ := svd.Exec(v)
bit := getMarkBit(blockAt)
s[0], s[1] = embedFunc(s[0], s[1], bit)
isvd()
idct()
// 再びsrcへコピー
set(src, startX, startY, b)
blockAt++
}
}
dist := dwt.HaarIDWT(wavelets, srcWidth, srcHeight, nil)
_ = dist
// After
// 並べ替え用のIndexマップを作成
blockMap := dwt.NewBlockMap(waveletWidth, waveletHeight, waveletBlockWidth, waveletBlockHeight).GetMap()
// 並べ替え済みの一次元スライス
wavelets := dwt.HaarDWT(img, srcWidth, blockMap)
src := wavelets[0] // cA
totalBlocks := (waveletWidth / waveletBlockWidth) * (waveletHeight / waveletBlockHeight)
for at := range totalBlocks {
// srcの参照
block := src[at*waveletBlockWidth*waveletBlockHeight : (at+1)*waveletBlockWidth*waveletBlockHeight : (at+1)*waveletBlockWidth*waveletBlockHeight]
v, idct := dct.Exec(block)
s, isvd, _ := svd.Exec(v)
bit := getMarkBit(at)
s[0], s[1] = embedFunc(s[0], s[1], bit)
isvd()
idct()
// それぞれ参照先へ逆変換を割り当てているためsrcに値が戻る
}
dist := dwt.HaarIDWT(wavelets, srcWidth, srcHeight, blockMap)
_ = dist
コード: https://github.com/yyyoichi/watermark_zero/commit/6cbec1bb68adbe2ecd96ae8b93d896311e2f380d
計測結果
▶ ベンチマーク詳細
ブロックサイズは8(wavelets変換で4になります)で、SHD, FHD, 4K サイズで比較しました。
go test ./bench -benchmem -bench BenchmarkBlockMap --benchtime 10s -cpu 1,2,3,4 -count 2
goos: linux
goarch: amd64
pkg: github.com/yyyoichi/watermark_zero/bench
cpu: Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz
BenchmarkBlockMap/noBlockMap_1280x720 96 121957257 ns/op 43928577 B/op 432065 allocs/op
BenchmarkBlockMap/noBlockMap_1280x720 87 119609855 ns/op 43911349 B/op 432040 allocs/op
BenchmarkBlockMap/noBlockMap_1280x720-2 102 116399734 ns/op 43918409 B/op 432052 allocs/op
BenchmarkBlockMap/noBlockMap_1280x720-2 103 115051393 ns/op 43918628 B/op 432054 allocs/op
BenchmarkBlockMap/noBlockMap_1280x720-3 104 114422260 ns/op 43924385 B/op 432060 allocs/op
BenchmarkBlockMap/noBlockMap_1280x720-3 96 114612915 ns/op 43925061 B/op 432062 allocs/op
BenchmarkBlockMap/noBlockMap_1280x720-4 104 114336974 ns/op 43928029 B/op 432064 allocs/op
BenchmarkBlockMap/noBlockMap_1280x720-4 88 114416441 ns/op 43927747 B/op 432063 allocs/op
BenchmarkBlockMap/withBlockMap_1280x720 86 117949790 ns/op 41157083 B/op 417646 allocs/op
BenchmarkBlockMap/withBlockMap_1280x720 88 122248001 ns/op 41145883 B/op 417632 allocs/op
BenchmarkBlockMap/withBlockMap_1280x720-2 88 118033696 ns/op 41150078 B/op 417639 allocs/op
BenchmarkBlockMap/withBlockMap_1280x720-2 86 117828413 ns/op 41150080 B/op 417639 allocs/op
BenchmarkBlockMap/withBlockMap_1280x720-3 88 117709383 ns/op 41154761 B/op 417644 allocs/op
BenchmarkBlockMap/withBlockMap_1280x720-3 88 117762902 ns/op 41155050 B/op 417645 allocs/op
BenchmarkBlockMap/withBlockMap_1280x720-4 87 117927198 ns/op 41156935 B/op 417645 allocs/op
BenchmarkBlockMap/withBlockMap_1280x720-4 90 117957209 ns/op 41157569 B/op 417646 allocs/op
BenchmarkBlockMap/noBlockMap_1920x1080 44 254826147 ns/op 98821574 B/op 972065 allocs/op
BenchmarkBlockMap/noBlockMap_1920x1080 44 264941760 ns/op 98802756 B/op 972038 allocs/op
BenchmarkBlockMap/noBlockMap_1920x1080-2 45 258642176 ns/op 98811652 B/op 972053 allocs/op
BenchmarkBlockMap/noBlockMap_1920x1080-2 43 255359455 ns/op 98809893 B/op 972052 allocs/op
BenchmarkBlockMap/noBlockMap_1920x1080-3 43 255276244 ns/op 98818638 B/op 972061 allocs/op
BenchmarkBlockMap/noBlockMap_1920x1080-3 45 255466291 ns/op 98817710 B/op 972060 allocs/op
BenchmarkBlockMap/noBlockMap_1920x1080-4 44 256113600 ns/op 98823189 B/op 972067 allocs/op
BenchmarkBlockMap/noBlockMap_1920x1080-4 45 256175622 ns/op 98820985 B/op 972066 allocs/op
BenchmarkBlockMap/withBlockMap_1920x1080 43 265378407 ns/op 92588334 B/op 939647 allocs/op
BenchmarkBlockMap/withBlockMap_1920x1080 40 271193171 ns/op 92576906 B/op 939634 allocs/op
BenchmarkBlockMap/withBlockMap_1920x1080-2 42 262745753 ns/op 92579560 B/op 939638 allocs/op
BenchmarkBlockMap/withBlockMap_1920x1080-2 42 262224028 ns/op 92580600 B/op 939640 allocs/op
BenchmarkBlockMap/withBlockMap_1920x1080-3 42 263259068 ns/op 92586136 B/op 939647 allocs/op
BenchmarkBlockMap/withBlockMap_1920x1080-3 42 263080892 ns/op 92586029 B/op 939646 allocs/op
BenchmarkBlockMap/withBlockMap_1920x1080-4 42 263668150 ns/op 92587988 B/op 939647 allocs/op
BenchmarkBlockMap/withBlockMap_1920x1080-4 43 263996282 ns/op 92587382 B/op 939646 allocs/op
BenchmarkBlockMap/noBlockMap_3840x2160 10 1013895857 ns/op 395058336 B/op 3888064 allocs/op
BenchmarkBlockMap/noBlockMap_3840x2160 10 1021764291 ns/op 395041662 B/op 3888044 allocs/op
BenchmarkBlockMap/noBlockMap_3840x2160-2 10 1007760872 ns/op 395049423 B/op 3888053 allocs/op
BenchmarkBlockMap/noBlockMap_3840x2160-2 12 1009751876 ns/op 395050734 B/op 3888055 allocs/op
BenchmarkBlockMap/noBlockMap_3840x2160-3 10 1009557056 ns/op 395055084 B/op 3888065 allocs/op
BenchmarkBlockMap/noBlockMap_3840x2160-3 12 1011831316 ns/op 395053463 B/op 3888062 allocs/op
BenchmarkBlockMap/noBlockMap_3840x2160-4 10 1012322098 ns/op 395057068 B/op 3888062 allocs/op
BenchmarkBlockMap/noBlockMap_3840x2160-4 10 1012902691 ns/op 395056931 B/op 3888065 allocs/op
BenchmarkBlockMap/withBlockMap_3840x2160 10 1050244693 ns/op 370169001 B/op 3758449 allocs/op
BenchmarkBlockMap/withBlockMap_3840x2160 10 1069734389 ns/op 370156368 B/op 3758431 allocs/op
BenchmarkBlockMap/withBlockMap_3840x2160-2 10 1059889272 ns/op 370163527 B/op 3758442 allocs/op
BenchmarkBlockMap/withBlockMap_3840x2160-2 10 1050247929 ns/op 370163057 B/op 3758441 allocs/op
BenchmarkBlockMap/withBlockMap_3840x2160-3 10 1047074380 ns/op 370168936 B/op 3758451 allocs/op
BenchmarkBlockMap/withBlockMap_3840x2160-3 10 1047546085 ns/op 370167361 B/op 3758450 allocs/op
BenchmarkBlockMap/withBlockMap_3840x2160-4 10 1047713375 ns/op 370170285 B/op 3758450 allocs/op
BenchmarkBlockMap/withBlockMap_3840x2160-4 10 1053755803 ns/op 370169924 B/op 3758450 allocs/op
マルチコアでも対して実行速度に差がない
メモリの割当効率は改善しましたが、速度はほとんど変化なし・やや遅いという結果でした。
改善
改善策として、スライスの順番を変更するときに、ループで一つずつ回しているため、効率が悪い可能性があります。 時間があれば改善、再計測可能かもです。
// 現状の一次元スライスの変換方法
blockMap := []int{
1,2,5,6,9,10,
3,4,7,8,11,12,
13,14,17,18,21,22,
15,16,19,20,23,24,
}
for i, v := range blockMap {
dist[i] = src[v]
}
// 以下のようにできれば、あるいは?
for i, chunk := range chunks {
copy(dist[chunk], src[chunk])
}
原因反省
CPUキャッシュを活かす方向で「ランダムアクセスを減らそう」とする意図もこの事前並べ替えの目的にありましたが、 大して活かせていないのかもしれないです。
原因考察はAIに事実認定されるのも嫌なので書かないでおきます。
以上!
背景
「わたしが描いた」を証明できるウォーターマークツール作っています。
インターネット上のだれでも「あたなの作品なんだね」と分かります。あとから「これは無断転載です」「これはAIじゃありません」といえるように作りました。